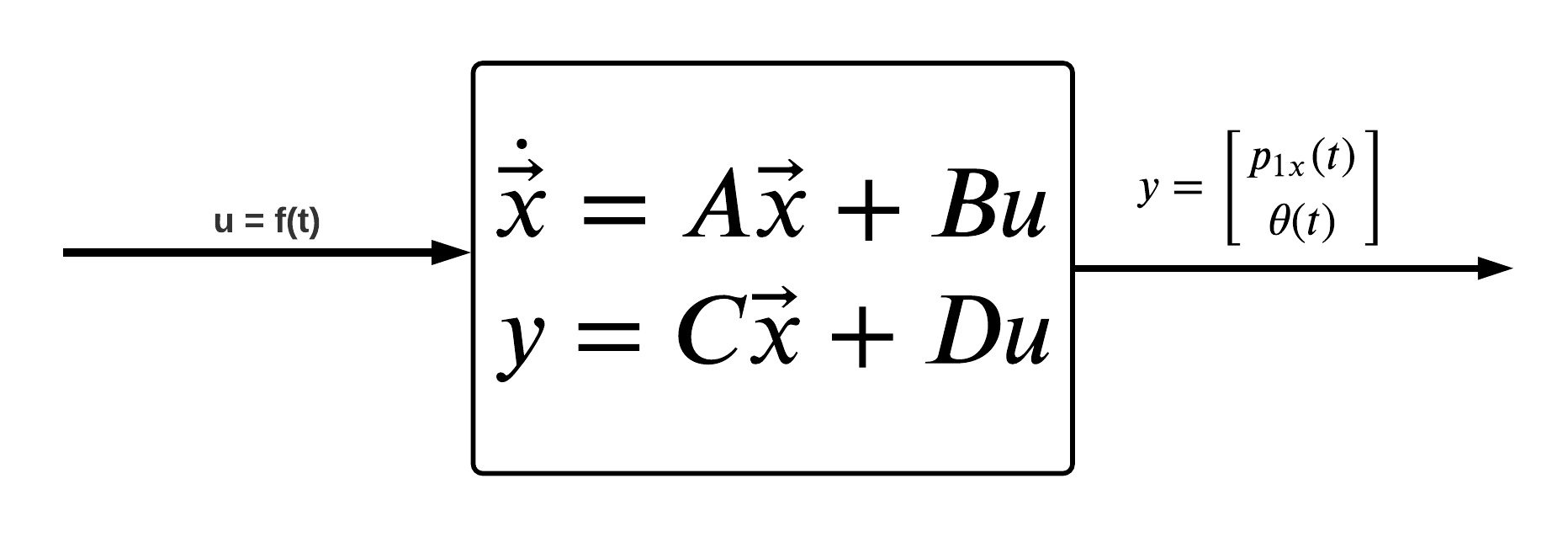Suppose we have a mass attached to a cart depicted in following diagram:

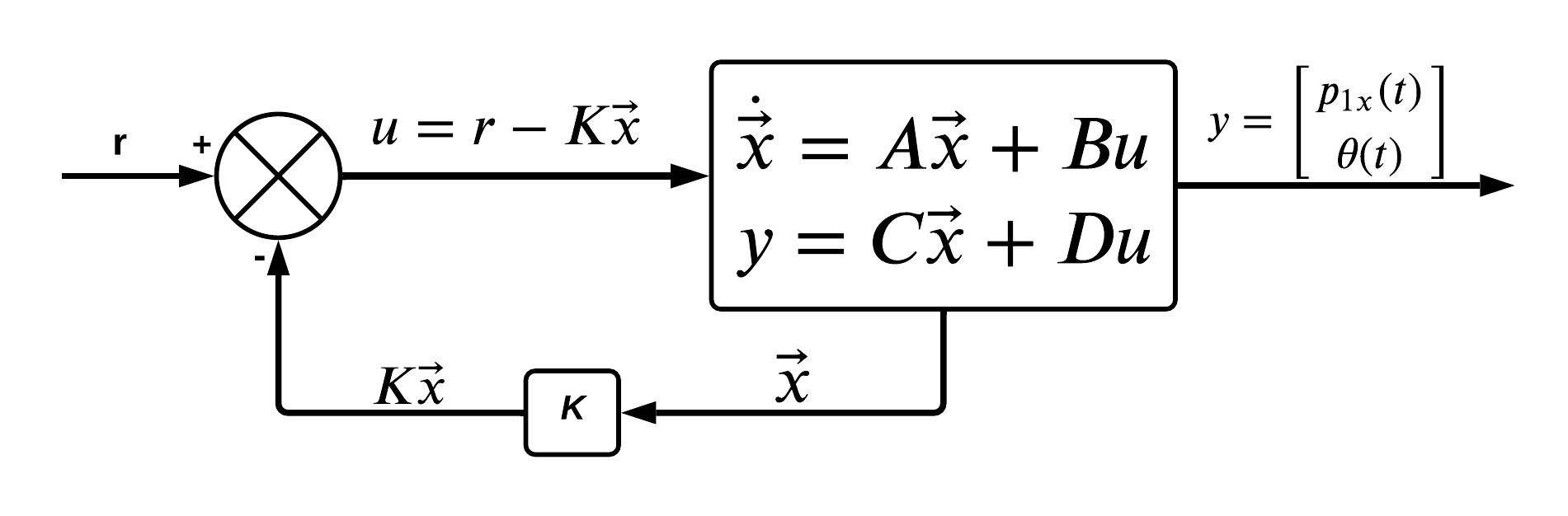
We wish to control the system such that the $m2$ mass will remain in the upright and vertical position. To keep the $m2$ mass in the upright vertical position i.e. keeping $\theta = 0$, we will be applying some force $f(t)$ on the $m1$ mass in the horizontal direction. To determine the magnitude and direction of the force needed to keep the $m2$ mass balanced, we will be using a full state feedback controller.
In order create a state feedback controller to balance our $m2$ mass, we must first come up with a mathematical model of our system, a.k.a the equations of motion (EOM). For this exercise, we opted to use Lagrangian mechanics to derive our EOM.
Note: We could have derived the EOMs using Newton's 2nd law, but found the math to be much more simple when using the Lagrangian.
In order to use the Lagrangian, we must fully describe the kinetic and potential energies of the system. This is more easily achieved if we add a few position vectors to our system diagram: 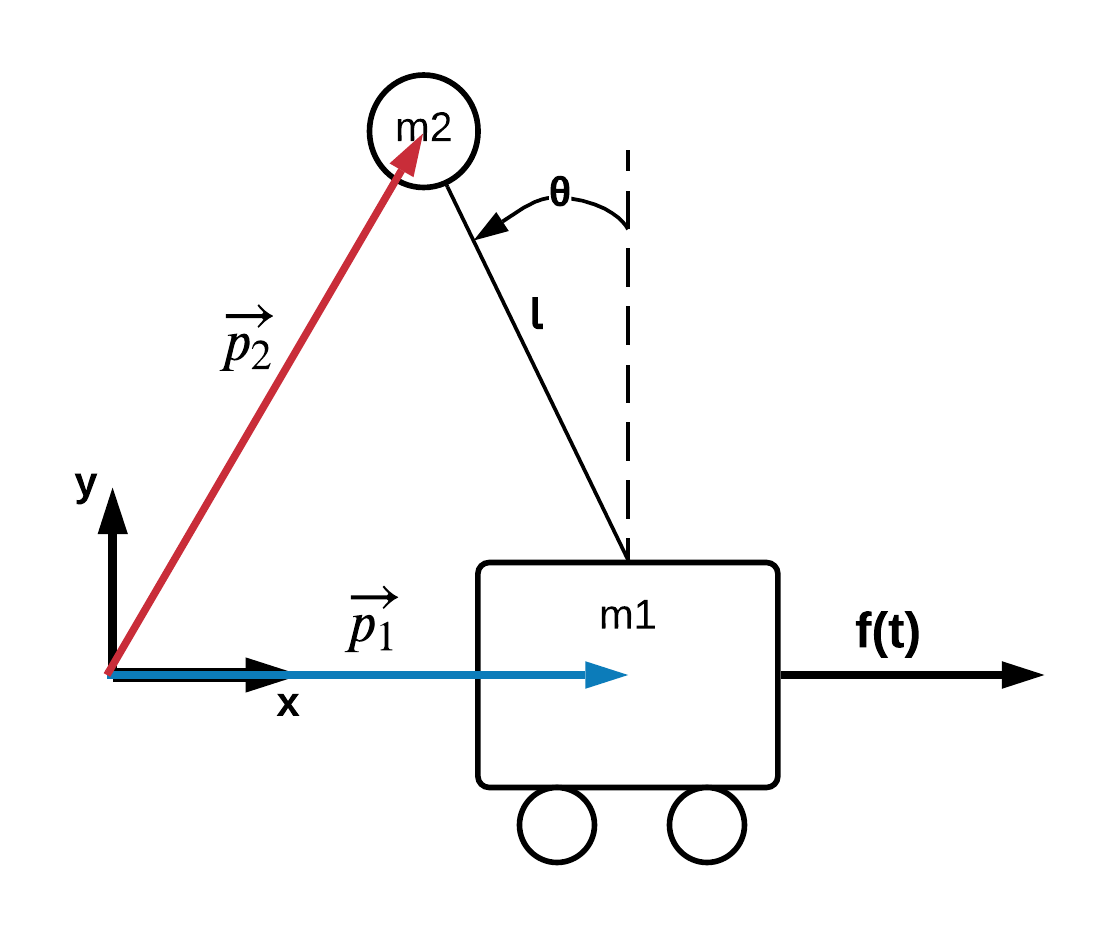
With the vectors $\vec{p_1}$ and $\vec{p_2}$ we can now describe the kinetic and potential energies as follows:
$$ KE = \frac{1}{2} m_1 \lvert \dot {\vec p_1} \rvert ^2 + \frac{1}{2} m_2 \lvert \dot {\vec p_2} \rvert ^2 \\ \tag{1} \label{keNotUseful} $$$$ PE = m_2 g l cos(\theta) \\ \tag{2} \label{pe} $$While the equation listed at $\eqref{keNotUseful}$ is very true, it is not very helpful. When we go to implement, we will not be able to directly measure or approximate $\vec p_2$ or $\dot{\vec p_2}$. We can however solve for $\vec p_2$ and $\dot{\vec p_2}$ in terms of other variables we can measure and approximate such as $\vec p_1$ and $\dot {\vec p_1}$.
Note: In the controls world, we typically call the variables that we can measure and/or calculate in real-time 'states'.
Consider our system but while only looking at the following vectors: 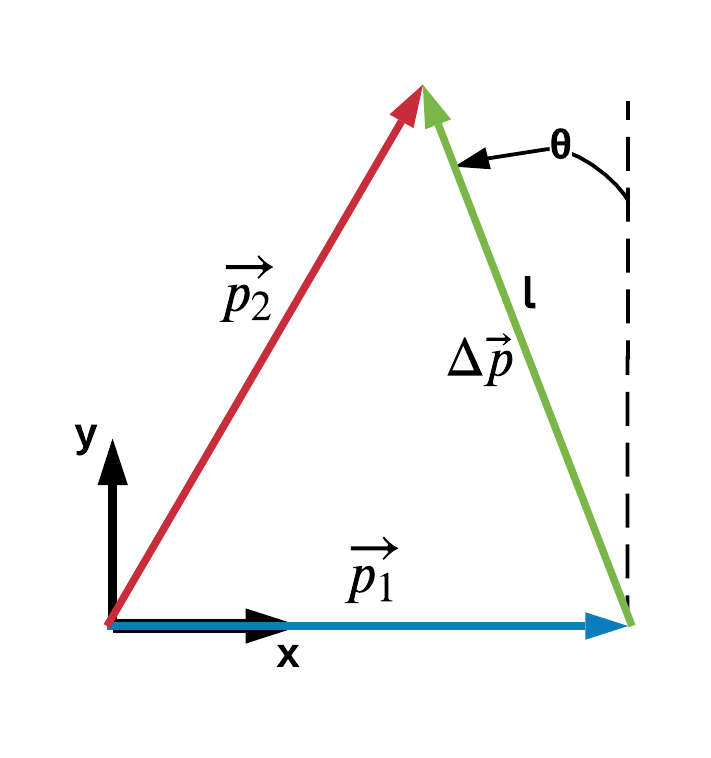
We can say that $$ \vec{p_2} = \vec{p_1} + \Delta \vec{p} \\ \tag{3} $$
Using the vector diagram, we can substitute useful relationships for $\vec{p_1}$ and $\Delta \vec{p}$ to represent $\vec{p_2}$ in terms of states that we can measure or approximate.